I do have lots of complaints about wayland current input method protocols. Some of them are just lacking features, but this issue is the one that I think have design flaw from the beginning.
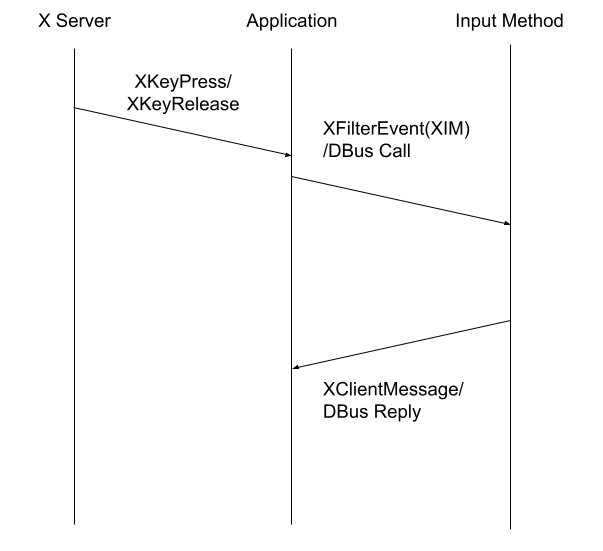
Let’s first review how the keyboard event is handled with input method on Wayland and X11.
The XFilterEvent would use XClientMessage to transport the key event to input method, which would actually introduce another message to X Server which is omitted in the graph above. Other than the XClientMessage, other methods may also be used, including raw socket, or DBus which is used by fcitx/ibus.
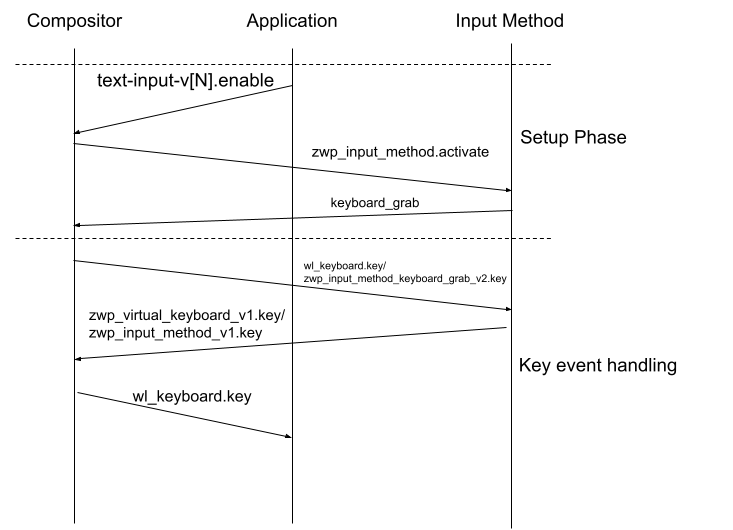
In Wayland, the things become different.
The input method first places a keyboard grab, to make compositor send all key event to input method server first. Then, depending on the result of key event (filter or not), the input method server may forward the key event back to compositor, then the key event will be forwarded from compositor to application, if input method server find this key is not relevant to the input method engine’s logic.
It may look ok right now, but if you put key repetition into consideration, you’ll find more issues with this design.
Imagine a following scenario:
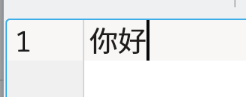
1. User is using an editor to type some text, and already have some text in application already. Let’s just say there’s some existing Chinese text: 你好.
Literally this means “hello” in Chinese 🙂
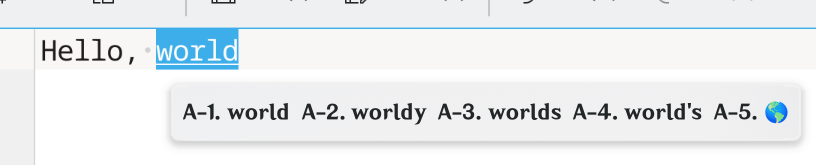
2. User types some new text and the text is stored in input method’s buffer to be converted to another language.
Hello, world!
3. User thinks that all the text is unwanted so the user press backspace and hold it, expect key repetition to remove the whole line, including “shi jie” and 你好 which is already committed.
Here is where it becomes problematic when Wayland decides to use keyboard grab for input method, and client side key repetition.
In X11, key repetition is done on the X Server side, client doesn’t need to worry about the key repetition generation. Client will just receive multiple key press events (release is optional, depending on a “detectable key repetition” option) until the key is physically released.
In Wayland, the key repetition is done on the application(client) side, the common logic is to implement this feature is that, when client gets a wl_keyboard.key press, it will start a timer and generate new key event on its own.
When you put input method in to this example, you will notice that, the very first “Backspace” is forwarded to input method and is invisible to client. So client will not be able to initiate the key repetition logic. That means, if the key need to be filtered by the input method, the input method server have to do the key repetition on its own.
In the case above, since there are texts in the buffer (shi jie), the first backspace will delete “e” in the buffer, then “i”, and then “j” etc..
When the last character in the buffer “s” is deleted, the buffer will become empty, which means, the next “repeated” backspace event need to be forwarded to application. This can still be done via zwp_virtual_keyboard_v1 or zwp_input_method_v1 depending on which version of protocol you are using.
Expected backspace behavior
But the problem is that, what do to next?
Let’s suppose the key repetition option is that “initial delay is 600ms, the repeat rate is 25/s”. The re-injected backspace can only trigger client’s own key repetition after 600ms, while user would expect it is already in the repeat phase, which will generate a backspace every 40ms. So input method have to continue to generate key press since application does not know the key repetition is already started in the past. But, after the first fake key repetition from input method is re-injected to the application, the client side key repetition logic will be now triggered. If input method doesn’t do anything to prevent it, the client will start to trigger key repetition after 600ms. If that happens, we will see both input method and client generating key repetition at the same time. To prevent this from happening, fcitx5 does a workaround by always sending a fake key release immediately after it send a key repetition from the input method side in order to stop the just started client side key repetition timer.
This seems to be very hacky and unreliable to me, since we are trying to “take over” the key repetition on client side, instead of hand it over.
Lets consider another scenario where it is totally broken.
Imagine a input method that can dynamically convert the text around cursor into preedit, and shows alternative text for the word around cursor. This is very common on mobile phone: you can click on a word and the word will be “underlined”, and alternative candidates is shown on the on-screen keyboard.
1. Image user have text “Hello, world |” (| represent the cursor location in application.
2. user starts to press backspace.
3. the first backspace press is ignored by input method, since there’s no word around cursor.
4. client side key repetition kicks in. Please notice that client side key repetition will not be forwarded to input method under current version of protocol
5. Text becomes “Hello, world”, and input method will try to consume “world” and convert it into preedit text and put “world” in the buffer on the input method server. Which means, from this point, any new backspace event should be handled by input method.
Consume the word “world” is and convert it to preedit is not a feature currently supported under fcitx, but we do want to implement such things in the future. Actually, fcitx5-unikey is already able to do something in a similar way, see the video below.
fcitx5-unikey’s consume existing text and re-edit feature. It’s not triggered by “backspace” but “e” in this case, but you get my idea.
But if you remember how client side key repetition works, you will notice that it will never be forwarded to input method, thus the backspace is “leaked” from input method into application, and will cause unexpected behavior.
My proposed solution to solve this is that: just go back to the old X11 model of forwarding event to input method. The procedure would look like:
wl_keyboard.key send to application
text_input.key send key to input method through compositor, this includes all key events, including the repeated key events generated on the client side.
input method server forward it back with the old interface
application got the input method forwarded back event via a new event text_input.forward_key, instead of from wl_keyboard.key.
This introduce more round trips between compositor and application, but it solves the whole issue in a much more cleaner way comparing to the other solution I can think of. And this new interface can even help on other issue like type-to-search’s chicken-and-egg issue, also this may make browser happier by allow them to stick to the javascript key/IME event standard better.
If one want to stick to keyboard grab model, they may have to add a lot of tricky new events like “handover ongoing key repetition” etc, which from my point of view would introduce much more complexity and easier to go wrong.