
2022/06/29:感谢一些朋友的指正,更新了关于 rime 的一点信息。
写在开头的话:许多年前,在我才刚刚开始用 linux 的时候,刚好赶上了 Sunpinyin 的诞生。那个时候 Yong Sun 写了 Sunpinyin 代码导读。尽管那个时候因为知识的储备不够丰富,基本上没有能够理解文章的内容,但是现在回过头来的话,终于在 2017 年的时候,自己从头写了一个类似算法的输入法引擎,来代替早已过时的 Fcitx 4 中的默认拼音和码表。
虽然也许有人会有疑问,为什么要从头写这样一个输入法引擎,难道 Sunpinyin 不够好吗?我很久之前的一篇博客其实具体做出了一些功能上的解释。这里我们再重新从代码角度来解释一下 libime 的来龙去脉。
libime 目前的库分为 4 个部分,其中粤拼单独在一个Git 代码仓库里,粤拼大部分的代码是和拼音类似的。之后也不会特别介绍粤拼的部分。
另外一些原因是,其中很多核心的代码对我自己来说也已经不很熟悉了,也是趁此机会记录一下翻新一下自己的记忆。另外我相信这些经历的部分,对于了解 Linux 输入法和 Fcitx 的发展过程的也是很有趣的,当成一个故事来看大概也不错?
核心部分(Core)
在解说 Core 之前,就要说到为什么要写 libime 这件事。而这就不得不说说之前的几个前辈们,有些我只有大致的了解,所以可能有错误。首先是 fcitx4 的拼音输入,它的基本原理就是 Forward maximum matching,简单来说就是根据你当前的输入,找到词库中最长能匹配它的内容。这个算法本身在汉字分词的领域也有应用,优点当然就是快,缺点也很明显,就是给出的提示不够准确,没有句子的概念。而 Sunpinyin ,是一个基于N-gram统计语言模型的输入法。它根据拼音匹配到的词来计算一个最终句子的概率,从中将结果按照概率高低进行排序。
(更正一下关于 Rime 的信息) Rime 几年前确实没有语言模型,或者说只是类似 Unigarm 的算法 ,2019 年左右加入了 一个 bigarm 的实现。然而根据搜索对应的文件名,似乎没有哪个 Linux 发行版打包了对应的数据…所以可能根本也没什么人实际用上了 rime 的这个功能。
但 Sunpinyin 作为实现输入法来说,缺少很多丰富功能方面的 API,例如词库只有一个。也没有特别方便的修改词库的方式。另外词库本身还是采用 sqlite 进行存储,对输入法来说并没有很大的必要。
因此,libime 的核心目标就是,实现一个类似 Sunpinyin 的基于 N-gram 的输入法引擎,并且需要可以方便地支持我需要的功能,包括多词库等功能。
作为 Fcitx 4 的精神续作,我还希望它能够占用尽量少的资源。
作为核心部分,我主要想要包括的数据结构包括两个,Trie 和语言模型。如果查看早期的历史的话,可以看到好几种已经删掉的 Trie 的代码的实现。如果学习过数据结构代码的话,可能会知道 Trie 是一个表示树的数据结构,适合存储许多字符串。当你在 trie 上游走的时候,根据字符串当前字母的位置就可以找到其他匹配这个前缀的节点。
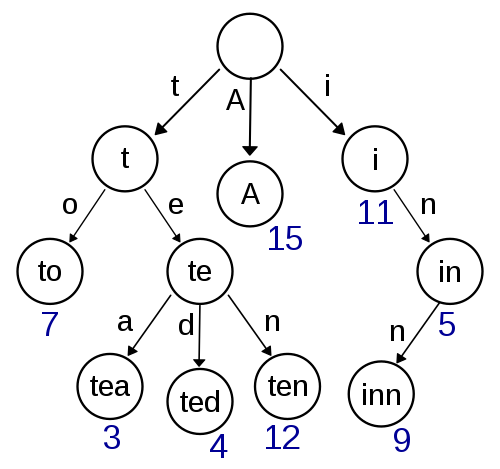
其中我对于它的数据结构功能的要求主要是这样的:
1、可以在运行时修改(有一些 Trie 的实现是无法动态修改的)
2、内存占用紧凑
在尝试了多个实现之后,最后采用了 double array trie 作为 Trie 的实现,采用了 cedar 的代码作为实现,但把其中可以用 C++ 标准库替代的部分都进行了替代从而精简了许多不需要的代码。这其中还踩了一个坑,简单来说就是 std::vector 替代之后的性能不如原本的性能,最终发现原因是 C++ 的 allocator 没有能对应 realloc 的函数。在可以原地 realloc 的时候,可以节省很多操作。因此又实现了一个 naivevector ,把 std::vector 里面实现替换成采用 malloc 和 realloc 的,从而获得了和原版类似的性能。
而语言模型我则找到了 kenlm 作为实现,在其上封装了对应的 API 方便调用。对应的就封装在 LanguageModel 类中。kenlm 提供了多种存储方式这里 libime 直接采用了一种内存占用较小的选项。
到此 Core 中两个核心数据结构的问题就都解决了。
kenlm 提供的核心功能就是给出一个当前状态,查询对应的词的概率。
LanguageModel model(LIBIME_BINARY_DIR "/data/sc.lm");
State state(model.nullState()), out_state(model.nullState());
std::string word;
float sum = 0.0f;
while (std::cin >> word) {
float s;
WordNode w(word, model.index(word));
std::cout << w.idx() << " " << (s = model.score(state, w, out_state))
<< '\n';
std::cout << "Prob" << std::pow(10, s) << '\n';
state = out_state;
sum += s;
}
State 保存了当前的状态信息,本质上就是存储之前出现的 WordNode 有哪些,从而计算对应的下一个词出现的概率。概率的数值都采用对数。因此只需要将获得的概率简单相加,即可得到整体的概率。
在有了 Trie 和语言模型之后,Core 最后要提供的核心功能就是利用 Trie 和模型进行搜索,来获得最终的匹配的句子的结果,这个过程在 NLP 中一般称做 decode。对应的实现在 libime 里就放在了 Decoder 里。这里采用的算法就是 Viterbi。当然,为了简化做了对应的剪枝,整体的算法一般被称做 Beam search。(非NLP 专业,用词可能有不准确的地方)
而在此之前,我们先回到我们需要实现的输入法上来,这样才能更好的讲解这里算法是怎么起作用的。
首先我们要提到的就是这个类,SegmentGraph。它表示的是将字符串切分的方式的图。其中每个可以切分的节点都是图中的一个节点。对应到拼音当中,就是拼音进行切分的方式。切分的方式是完全的。对于一个最复杂的情况来说,例如(anana),可能的切分就是这样的。
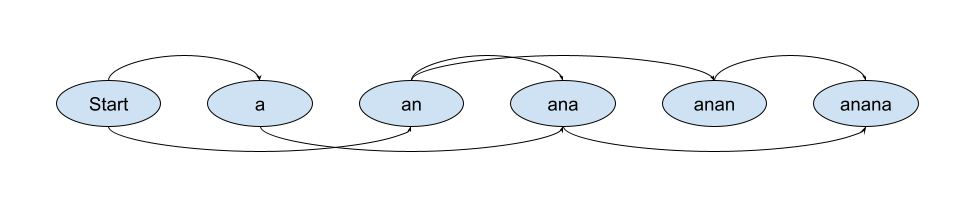
对应表示了 a na na,an a na,an an a 三种切分方式。
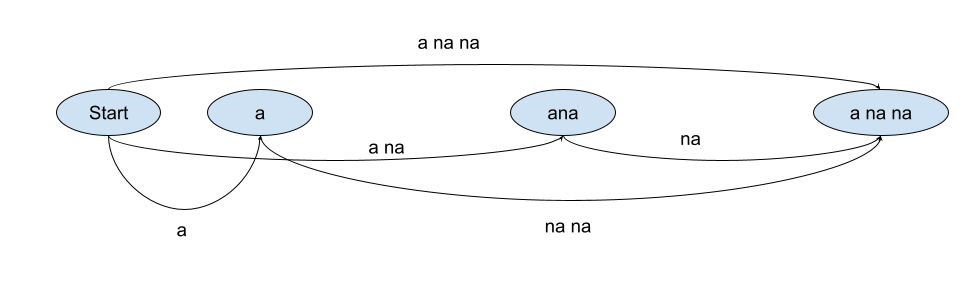
decoder 的输入是一个 Segment Graph,而输出则是一个 Lattice(网格)。这里发生了什么呢?简单来说,就是把 Segment Graph 的上每一条路径,都放到词典上去匹配。具体采用的匹配方式由词典决定。例如,对于上面的例子,a na na 这种切分,就要匹配 a na na,a na,a,na na,na 几种不同的路径。针对这种路径构建出来的 Lattice 就类似:
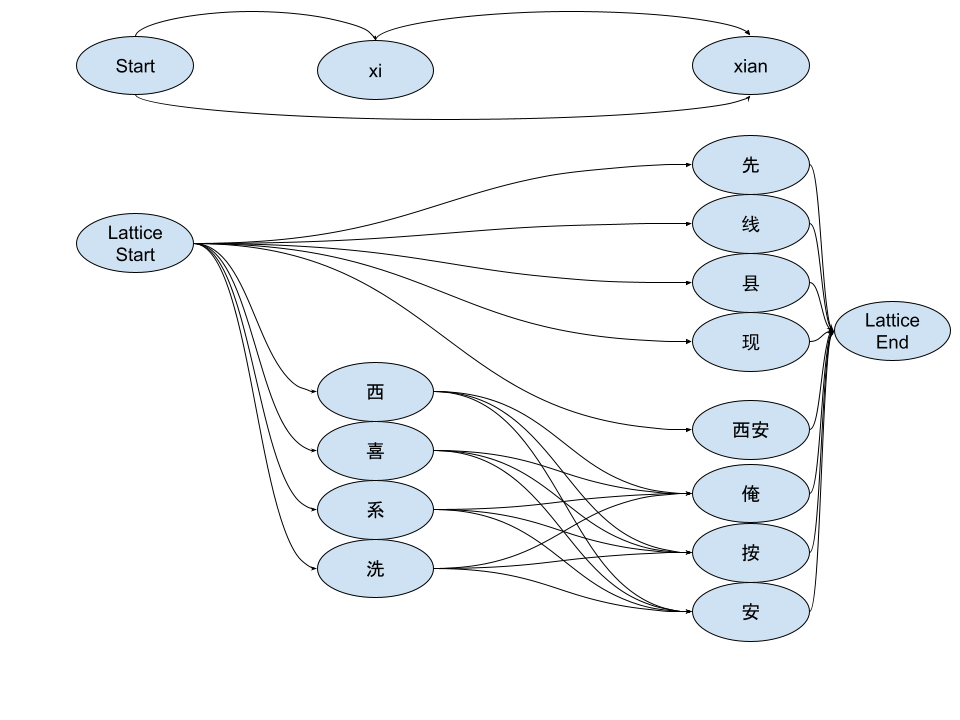
这里我们稍微换一个别的例子来进行解释。例如拼音内切分的经典例子xian(xi an)。在 xian 这个前缀所对应的节点,我们就有通过 xian 作为整体匹配的「先,线,县,现……」。而在 xi 这个前缀节点,则只有 xi(西,喜,系,洗……),然后这些 xi 的节点又通过 an 可以到达 xian 这个 SegmentGraphNode。例如有 an 「俺,按,安,……)。最后,还有直接通过 xi an 作为整词到达 xian 的(西安)。
在建立好 Lattice 之后,就是经典的 Beam search 发挥作用的地方了。通过动态规划的方式计算每条可能路径的概率(或称作score),在某些情况下会减少可能的搜索结果,否则可能搜索空间巨大。
这里的 Beam search 整体来说分成三个步骤,第一步就是上面说的构建 Lattice(网格),第二步 forward search,第三步 backward search。
第二步 forward search 的基本步骤就是,广度优先遍历 Segment Graph 上的所有节点,或者换句话说,就是遍历所有可能的切分点(不论切分路径为何),然后计算切分点 Segment Graph Node 对应的 Lattice Node 的最高得分,计算方法就是找到 Lattice Node 对应的 Segment Graph Node 的父 Segment Graph Node。这个节点是唯一的,因为 Lattice Node 是通过计算某段拼音匹配的词找到的。然后针对这个父 Segment Graph Node 内的 Lattice Node 进行遍历,计算其中的最高分。简单来说就是 latticeNode.score = latticeNodeFrom.score + languageModel.score(latticeNodeFrom.state, latticeNode.word) 。这样不断求解,直到求出 Lattice End Node 的得分。
而 Backward Search 的主要目的是计算 N-Best score,如果只需要一个结果的话,那显而易见就是 Lattice End Node 的最高分对应路径。但怎么求解次一级的得分的路径呢?
简单来说就是从结尾倒推回去。最高分的 Lattice Node 的父 Segment Graph Node 的其他候选替换,来对比获得更好的结果。


2 Responses to libime 原理介绍(一)