
首先来讲一些历史,在更加久远的 Fcitx 3 的时代,Fcitx 的码表文件是使用 gb18030 存储的。在 Fcitx 3 -> Fcitx 4 的过程中,所有的文件都被替换为了 UTF-8,但是受限于当时的 glibc,出现了很多转换的结果是 PUA 区的情况(Private Use Area)。从根本上来说,导致这个的原因是 Unicode 标准仍未收入这些文字,因此采用 PUA 存储这些文字的权宜之计。
Unicode 有一些历史文档记载这些,但是并不是所有我们遇见的字符都记载其中 https://www.unicode.org/L2/L2004/04161-hkscs-gb-pua.pdf
但是时过境迁,现在已经过去十几年了,因此这些 PUA 的字符也都获得了对应的码位。也就是说,是时候把他们重新拉出来更新了。
对于 fcitx5-chinese-addons 当中的码表(实际上是 libime 这个包),这倒不是一件难事。只需要把 fcitx3 的文件找回来,然后在新的 glibc 的系统上重新转换一次即可。为了验证当年的流程,我还特地安装了一个 debian 5 的系统重现当年的转换。
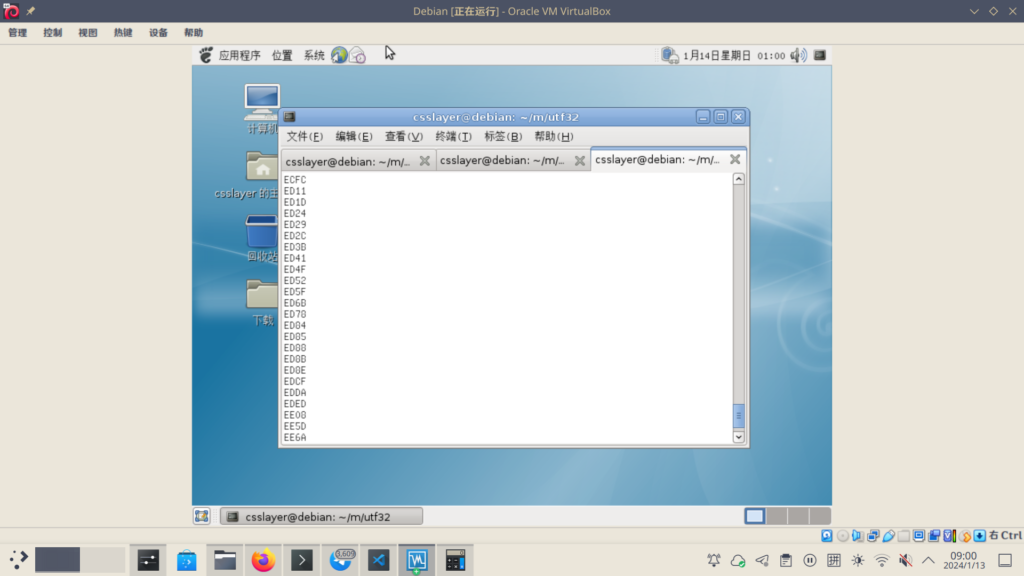
而这也确实证实了,当年确实是这样得到那些 PUA 的字符的。
而对于 fcitx5-table-extra 来说,这就有些难办了,他们当中的文件我们并没有原始的文件。这该怎么办呢?kingysu 发现 AR PL UMing HK 和 AR PL UMing CN 能够正确显示其中的大部分字符,而这正式取决于他们原始的文件的码是 BIG5-HKSCS,还是GB18030。
我们一开始的想法是全手动处理,一个个根据字形去查找对应的文字,据此我们也用了 https://www.qhanzi.com/index.zh-CN.html 一些手写中文识别的文字。还有用汉典 zdic 利用偏旁,仓颉,进行查询。
对于一些我们用以上方法都没找到的字符,我本来是想试试看用 fontforge 打开看看能不能直接搜索字形,然而我发现 fontforge 实际上对于 AR PL UMing 的字体可以显示他们实际引用的 unicode 的码。
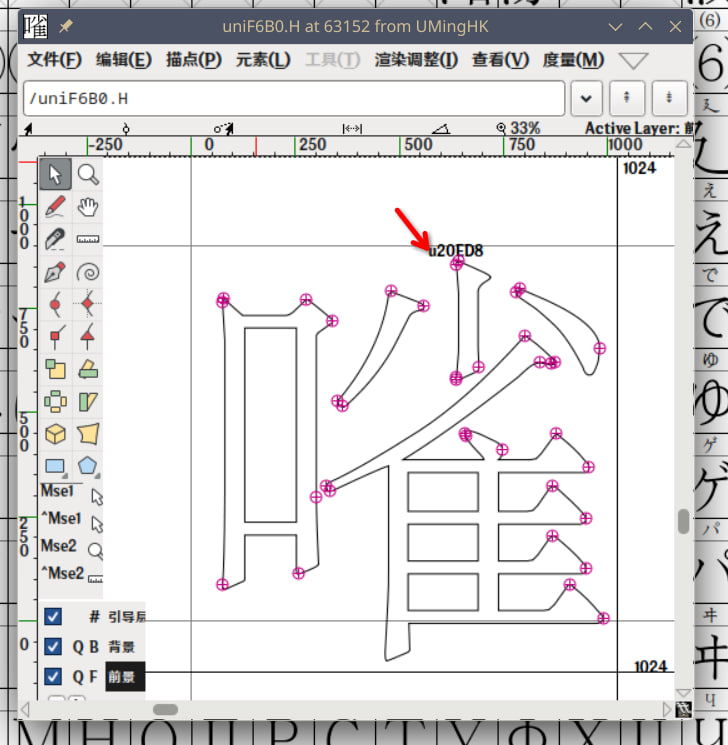
而 Rocka 提示我们,可以直接用 python-fonttools 的 ttx 直接导出字体的信息。实际上这里导出 glyf 表之后,可以获得形如

的文件。uniXXXX.H 是 Big5 的 PUA,uniXXXX.C 是 GB18030 对应的 PUA。剩下的工作就是直接写一些只用一次的垃圾小脚本把这些信息提取出来即可。因为写 Python 脚本的突出一个糙就不展示了。
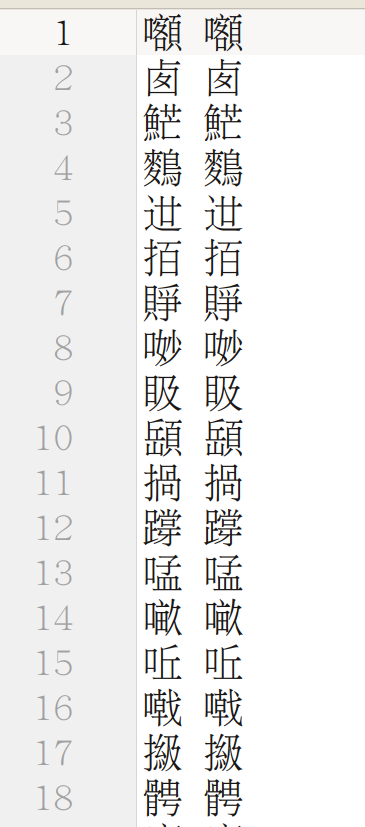
然后我们就得到了一个这样的映射,在 Uming 字体看看起来完全一致,但是实际上是不一样的 Unicode 哦。
如果用 Fcitx 的 Unicode 功能(复制然后Ctrl Shift Alt U)就可以容易地看出区别。
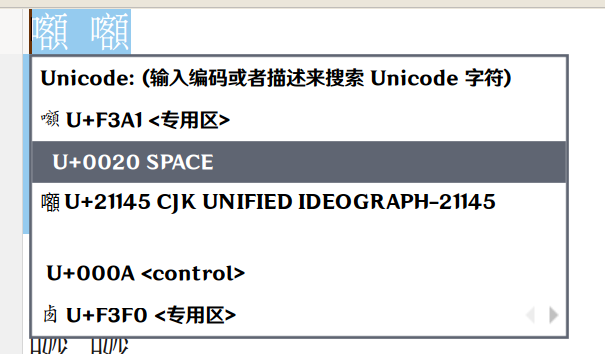
剩下就是把他们完全替换成正规的 Unicode 字符即可。
https://github.com/fcitx/fcitx5-table-extra/commit/0b3e04256b5b49c72a04e88da80bf34e5bba4b3f


好耶,我上电视了!
大佬,打扰您了,我最近编了一个riscv版本的fcitx5 用在我的weston桌面上。但是总是在快速输入字符的时候,拼音输入会退出,直到我再次对焦到输入框中才能Ctrl+space呼出中文输入法。 我是基于这个https://gitlab.com/clear-code/meta-inputmethod 项目的版本实现的。 在weston-editor和gtk应用中都会有这个问题,想问问是否是我这个fcitx版本太旧或者 weston不兼容这种?
@louis 请用 fcitx5 官方版本
如果你需要屏幕键盘,请考虑使用 https://www.csslayer.info/wordpress/fcitx-dev/%E6%BC%94%E7%A4%BA%E4%B8%80%E4%B8%8B%E5%92%8C-openkylin-%E5%90%88%E4%BD%9C%E5%BC%80%E5%8F%91%E7%9A%84%E8%99%9A%E6%8B%9F%E9%94%AE%E7%9B%98/ (用X11启动键盘界面 QT_QPA_PLATFORM=xcb)